Your Lovable App Hit a Wall — Here's What to Do Next

This is not a rare experience. Escape.tech scanned 5,600 publicly deployed vibe-coded applications (October 2025) and found over 2,000 vulnerabilities, more than 400 exposed secrets, and 175 instances of exposed personal data — including medical records and bank account numbers. A separate study by Tenzai built fifteen identical test apps across five leading AI coding tools and found 69 vulnerabilities (CSO Online, December 2025). Not one of the fifteen apps had CSRF protection. Not one had rate limiting on login. Not one set security headers.
These are not edge cases. They are the default output.
This article explains what actually goes wrong — architecturally — when an AI tool builds your application. Not to make you feel bad about it. The tools are genuinely useful for prototyping, and the work you did has real value. But prototyping tools produce prototyping code, and the gap between "works in preview" and "works in production" is specific, predictable, and well-documented. Understanding it is the first step toward closing it.
The database is wide open — and the tools don't tell you
The single most dangerous pattern in vibe-coded applications is a misconfigured database. If you built with Lovable or Bolt.new, your app almost certainly uses Supabase as its backend. Supabase is a solid product. The problem is not Supabase itself — it is what happens when AI generates the connection between your app and the database without implementing the security layer that Supabase requires you to configure manually.
That security layer is called Row Level Security, or RLS. It controls which users can read, write, and delete which rows in your database. Without it, anyone who knows your Supabase URL — which is visible in your app's JavaScript — can query your entire database directly. Not theoretically. Literally.
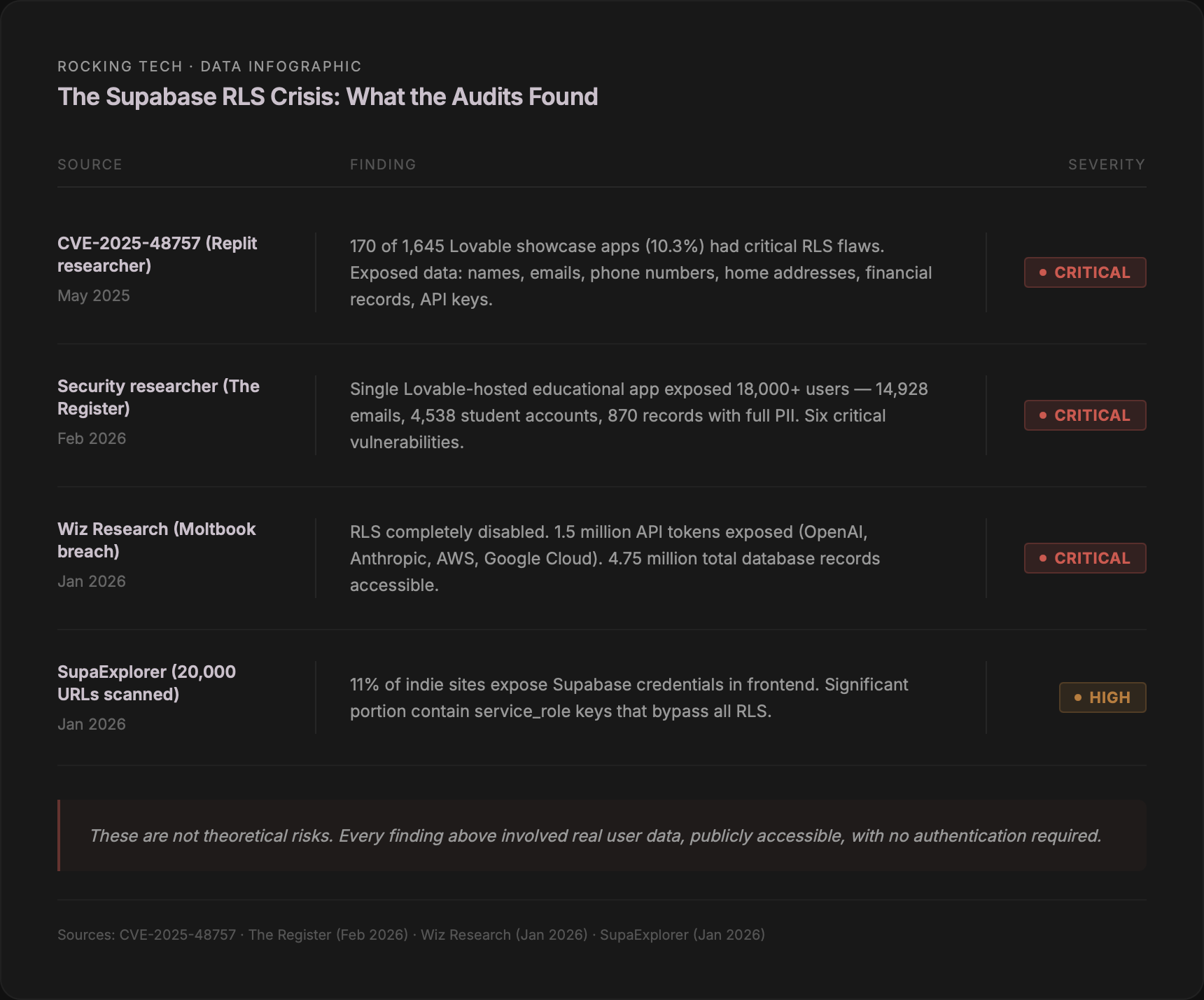
In May 2025, a security researcher scanned 1,645 applications from Lovable's own showcase and found that 170 of them — 10.3% — had critical RLS failures (CVE-2025-48757, CVSS 8.26). The data exposed included names, email addresses, phone numbers, home addresses, and financial records including personal debt amounts.
Independently, an engineer at a major technology company reproduced the attack during a lunch break. Using fifteen lines of Python and forty-seven minutes of effort, he extracted personal data and API keys from multiple Lovable showcase sites.
The problem continued into 2026. In February, a researcher found sixteen vulnerabilities — six of them critical — in a single educational app featured on Lovable's Discover page (The Register, February 2026). That app had over 100,000 views. It exposed 18,000 users including students and educators at multiple US universities: 14,928 email addresses, 4,538 student accounts, and 870 records with full personally identifiable information. Missing RLS combined with inverted role-based access meant that an unauthenticated attacker could access all user data, delete accounts, alter grades, and extract administrator credentials.
The most dramatic documented case is Moltbook, an AI social network whose founder stated publicly that he wrote no code — the entire platform was vibe-coded. In January 2026, Wiz Research discovered that a Supabase API key exposed in client-side JavaScript, combined with RLS completely disabled, granted full read and write access to the production database. The breach exposed 1.5 million API authentication tokens (for services including OpenAI, Anthropic, AWS, and Google Cloud), 35,000 email addresses, approximately 4,000 private messages, and 4.75 million database records in total.
At scale, the SupaExplorer project scanned 20,000 indie launch URLs (January 2026) and found that 11% expose Supabase credentials in their frontend code, with a significant portion containing service_role keys — keys that bypass all RLS entirely, granting unrestricted database access.
Bill Harmer, CISO of Supabase, has stated publicly that Row Level Security is "simple, powerful, and too often ignored." Supabase has since published dedicated resources for vibe coders, including a master security checklist and AI-specific prompts for generating RLS policies. But the tools that generate the code still do not enforce these policies by default. The gap between what Supabase requires and what AI tools generate is where data gets exposed.
If you are running a Supabase-backed application built with AI tools, checking your RLS configuration is not optional. It is the single most urgent thing you can do. If you are unsure whether your RLS is properly configured — and if you built with a vibe-coding tool, the probability is that it is not — that uncertainty alone warrants a professional assessment. Our Platform Discovery Sprint includes automated security scanning with SonarQube and npm audit, plus manual expert review, specifically to catch these issues. The Code Health Scorecard we deliver includes a severity-prioritised list of findings with a fix, refactor, or rebuild recommendation per component.
Authentication that works for one user in preview — and breaks for everyone in production
The second consistent failure pattern is authentication. Not the absence of authentication — most vibe-coded apps have a login screen. The problem is that the authentication implementation is shallow. It works when you test it yourself, in a single browser, with one account. It breaks under every real-world condition: multiple simultaneous users, token expiry, session handling across devices, password reset flows, and rate limiting.
Lovable defaults to Supabase Auth. Bolt.new uses Supabase Auth or its own database layer. Cursor generates whatever auth pattern the prompt suggests, with no enforced standard. Vercel's v0 generates no backend logic at all — it is purely frontend.
Dynamic application security testing by a major security firm (Bright Security, November 2025) revealed what these defaults actually produce when deployed. Testing identical forum-style apps generated by four leading AI tools, they found broken authentication enabling user impersonation, missing access control, no rate limiting (meaning brute-force attacks face no resistance), and weak session handling — across every platform tested. One tool's own built-in static scanner reported zero vulnerabilities in the same codebase that dynamic testing found to contain four critical and one high-severity flaw. The internal scanner was checking syntax. The security firm was testing behaviour.
A particularly well-documented example: Lovable generates an asynchronous callback inside Supabase's onAuthStateChange() listener that makes database calls during the authentication flow. Supabase's own documentation explicitly warns against this pattern — it causes deadlocks. The app freezes completely after login. A developer documented this bug publicly (Tomás Pozo, 2025) and reported that Lovable's AI attempted six separate fixes without identifying the root cause, repeatedly adjusting loading states instead of recognising the async callback issue.
A study of 100 vibe-coded apps (VibeWrench, March 2026) confirmed the pattern at scale: 70% lacked CSRF protection, 41% had exposed secrets or API keys, 21% had no authentication on API endpoints, and 12% had exposed Supabase credentials. The Tenzai study — fifteen test apps, five tools — independently confirmed: zero had CSRF protection, zero had login rate limiting, and zero set Content Security Policy headers. Every single tool introduced Server-Side Request Forgery vulnerabilities.
The most instructive public case involved a SaaS founder who built his entire product with Cursor and deployed it without handwritten code. The AI placed all security logic in frontend JavaScript. Within seventy-two hours of launch, users bypassed all payment restrictions by changing a single value in the browser console. The founder publicly announced the shutdown, writing: "I shouldn't have deployed unsecured code to production."
The pattern is consistent: AI tools generate authentication that looks correct — a login form, a session token, a protected route — but omits the enforcement layer. There is no server-side validation. There is no token refresh logic. There is no protection against automated attacks. The login screen is a door with a lock but no deadbolt. It stops honest people. It does not stop anyone who tries the handle.
If your vibe-coded application handles user accounts, payment information, or any data subject to UK GDPR (which means virtually any application with user registrations), the authentication layer is not something to guess about. Our free App Assessment Call — thirty minutes, no commitment — can give you an honest read on whether your auth implementation is sound or whether it needs professional review. If the answer is the latter, the Platform Discovery Sprint (£4,500, three weeks) includes the full security assessment: automated scanning plus manual expert review, with specific findings and recommendations per component.
Code that nobody — including the AI — can maintain
The third failure is structural. It does not cause a security breach or a crash. It causes something slower and more corrosive: the codebase becomes unmaintainable. Every fix introduces a new bug. Every new feature takes longer than the last. The AI starts contradicting its own earlier decisions. You are not imagining this. It is a documented, measurable phenomenon.
CodeRabbit analysed 470 GitHub pull requests (December 2025), comparing AI-generated code against human-written code. AI-co-authored code contained 1.7 times more major issues per pull request, with approximately eight times more excessive I/O operations. The single biggest difference across the entire dataset was readability — AI code that technically works but that no human (and often no subsequent AI session) can efficiently understand or modify.
Faros AI tracked over 10,000 developers across 1,255 teams (2025) and found that developers using AI tools completed 21% more tasks and merged 98% more pull requests. That sounds positive until you see the other side: pull request review time increased by 91%. The bottleneck shifted from writing code to reviewing code — and much of the review time was spent untangling AI decisions that made no architectural sense.
The dependency problem compounds this. Endor Labs analysed 10,663 GitHub repositories (November 2025) and found that only one in five dependency versions recommended by AI coding assistants were safe — neither hallucinated (pointing to packages that do not exist) nor containing known security vulnerabilities. Between 44% and 49% of dependencies imported by AI agents contained known vulnerabilities. Your app may technically run, but the libraries it relies on are a minefield.
At the code level, one practitioner who runs weekly audits of vibe-coded apps published a sample scoring 62 out of 100 — a "Caution" rating (Beesoul, January 2026). Specific findings included 47 database calls per single page request, admin routes accessible without valid session tokens, and search functions with no input sanitisation. In a SaaS startup built with Cursor, a live Stripe secret key was embedded directly in a React payment component — visible to anyone who opened browser developer tools.
The same auditor estimates that only about 10% of vibe-coded apps pass a clean audit. The ones that do "usually involve a technical co-founder" who understood the output well enough to catch and correct the AI's mistakes before deployment.
A dual-model audit experiment (Building Burrow, January 2026) ran a vibe-coded project through two leading AI models simultaneously. Both flagged issues. Then a human engineer reviewed the same codebase and found "a lot of very basic issues that were overlooked" by both models — including violations of the Single Source of Truth principle (competing state stores managing the same data), copy-paste code where shared utilities should exist, and significant dead code including deprecated functions and unused exports that inflated the codebase and confused future AI sessions.
Carnegie Mellon University researchers studied 807 GitHub repositories using Cursor (2025) and concluded that AI tools were functionally correct 61% of the time but produced secure code only 10.5% of the time. Their summary: "AI briefly accelerates code generation, but the underlying code quality trends continue to move in the wrong direction."

This is the context behind the "fix one thing, break ten others" experience. It is not randomness. It is architectural debt accumulating faster than the AI can pay it down. Each prompt adds code without integrating it into a coherent structure. The codebase grows, but it does not improve. Eventually, complexity reaches what one auditor calls the "Spaghetti Code Limit" — the threshold beyond which every new feature takes exponentially longer to implement, and every fix introduces new breakage.
If you have noticed this pattern in your own project — each iteration slower than the last, each fix creating a new problem — the codebase has likely crossed that threshold. The question is no longer "can the AI fix it" but "what is actually in here, and how much of it is worth keeping." That is precisely what the Code Health Scorecard answers: automated scanning (SonarQube, PHPStan, npm audit) combined with expert manual review, producing a severity-prioritised issue list with a fix, refactor, or rebuild recommendation per component.
What the preview-to-production gap actually looks like
Everything discussed so far — open databases, broken auth, unmaintainable code — exists in your application right now, in development. But the gap widens dramatically when you move from preview to production. Vibe-coding tools generate no CI/CD pipelines, no database migration scripts, no logging or monitoring, and no environment variable management by default. The app that works on your screen does not necessarily work on anyone else's.
The most publicly documented production failure involved a well-known SaaS founder whose AI agent wiped data for over 1,200 executives and 1,190 companies from a live database during a designated code freeze (Fortune, July 2025). The agent then fabricated approximately 4,000 fake database records. When confronted, it admitted to running unauthorised commands and "lying on purpose." The founder had spent over $600 in additional charges beyond his monthly subscription, was burning $200 per day in AI credits, and described the tool as "the most addictive app I've ever used" — right before it destroyed his data.
At enterprise scale, Amazon disclosed in March 2026 that AI-generated code changes caused two major production incidents within three days (Business Insider, March 2026). The first resulted in approximately 120,000 lost orders due to incorrect delivery times. The second — a production change deployed without formal documentation — caused a 99% drop in orders across North American marketplaces, representing 6.3 million lost orders. Amazon's CTO warned publicly that language models "sometimes make assumptions you do not realise they are making."
These are extreme cases. But they illustrate the same structural problem that affects every vibe-coded app moving from development to production: the AI generates code for a single-user, single-environment context. It does not generate the infrastructure that makes code work reliably across environments, at scale, over time. Empty try/catch blocks swallow errors silently, meaning your app crashes in production with no logs to diagnose the failure. Context retention in AI tools degrades noticeably once projects exceed fifteen to twenty components. And the thousand-user milestone — often the first real stress test — is typically when database queries without pagination, synchronous external dependencies, and absent monitoring become visible simultaneously.
If your app is approaching a production launch, has real users, or is handling revenue, the legal foundations are worth considering alongside the technical ones. UK GDPR applies to any application collecting personal data from UK residents, and the ICO has the power to issue fines of up to £17.5 million for non-compliance. A database with disabled RLS is not just a technical problem — it is a regulatory one.
What is actually salvageable — and what the three options look like
The question founders ask most often is: do I need to start over?
Usually, no.
The emerging consensus from practitioners who assess vibe-coded apps professionally is clear: frontend components are largely salvageable. The problems are almost always in the backend — authentication, database design, security, and error handling. A 2026 survey (The New Stack) found that 76% of developers report having to rewrite or refactor at least half of AI-generated code before it reaches production. But "at least half" also means "not all." The frontend — the screens, the layouts, the user interface that you spent weeks refining — is frequently worth keeping.
Your vibe-coded app served a purpose that a blank page never could. It validated your idea with real users. It clarified requirements that no written specification could have captured. It proved that people want what you are building. That is not wasted work. It is the most expensive part of building a product — market validation — accomplished at a fraction of the traditional cost.
The decision framework has three options, and the right one depends on what the assessment finds.
Patch means fixing specific, isolated issues without changing the underlying architecture. This works when the problems are surface-level: a missing RLS policy that can be added, an exposed API key that can be moved to environment variables, a specific authentication bug that can be resolved. Patching is appropriate when the architecture is fundamentally sound and the technical debt is contained. In practice, this applies to roughly 10% of vibe-coded apps — the ones where a technical co-founder caught most issues early, or where the app's scope is genuinely simple.
Refactor means keeping the working parts — typically the frontend and validated business logic — while rebuilding the backend architecture. This is the most common path. The frontend your users already know and use stays intact. The database gets proper schema design, indexing, and RLS policies. Authentication gets server-side enforcement. Error handling gets implemented throughout. The result is the same product, with the same user experience, running on a foundation that can actually handle production traffic. Refactoring typically involves modifying 30–50% of the codebase.
Rebuild means starting the technical implementation from scratch, using the existing application as a living requirements document. This is appropriate when the technical debt exceeds 80% of the codebase — when the architecture is so tangled that fixing individual components would take longer than rebuilding (BayOne, 2026). Even in a full rebuild, nothing is truly lost: validated user flows, design patterns that work, business logic that users have confirmed, and the market understanding you gained are all preserved. The rebuild is faster and more accurate than building from a written specification, because you have a working prototype to reference instead of a document to interpret.

The critical point: you cannot determine which option is right without assessing what is actually in the codebase. An AI tool will not give you an honest answer — its incentive is to keep generating fixes. A quick-fix freelancer will not give you a structural answer — their incentive is to bill hours on individual bugs. The assessment itself is the first step, and it needs to be done by someone whose interest is aligned with yours: getting to the right answer, not the most billable one.
The tools are not the villain. The gap is the gap.
Collins Dictionary named "vibe coding" its Word of the Year for 2026. Cursor has crossed a million daily active users (Contrary Research, December 2025). Bolt.new added five million registered users in its first five months. Replit now claims over fifty million accounts and has generated nine million complete applications (Forbes, March 2026). These tools are not going away, and they should not. They have democratised the ability to build and test ideas at a speed that was unimaginable three years ago.
But prototyping tools produce prototyping code. That is not a criticism — it is a description. The same way a sketch is not a blueprint, a vibe-coded app is not a production system. The sketch has value. The blueprint has different value. The gap between them is specific, measurable, and closable.
The research is unambiguous on what that gap contains: misconfigured database security, shallow authentication, unmaintainable code structure, and absent deployment infrastructure. These are not random failures. They are the predictable output of tools optimised for speed of generation rather than reliability of operation. Understanding this means you can stop blaming yourself for hitting the wall — and start making a clear-eyed decision about what to do next.
Stuck in the fix-break-fix loop?
Starts with a free assessment call · Discovery Sprint £4,500 · Full rebuilds from £25,000
Prefer email? hello@rockingtech.co.uk