Why Your Vibe-Coded App Keeps Breaking Every Time You Fix Something
This is not bad luck, and it is not a skill issue. It is the predictable output of four compounding technical limitations in how today's AI coding agents understand code. By the time a founder is 30 prompts deep and watching previously-working features vanish, the tool has quietly lost the thread: the context window is full, the generation is non-deterministic, the agent has no map of what depends on what, and it has been patching symptoms rather than causes.
The loop is escapable. The way out is architectural, not another prompt.
The loop has a signature, and it's in the literature
The pattern has a name in practitioner forums — "the doom loop" — and a clean mechanism in the research. A commenter on a 2025 Hacker News thread analysing the architecture behind Lovable and Bolt put it plainly: "I've tried several proof of concepts with Bolt and every time just get into a doom loop where there is a cycle of breakage, each 'fix' resurrecting a previous 'break'" (Hacker News, July 2025). A developer migrating off Lovable in r/vibecoding was more direct: "When the project advances, it ruins your existing code" (r/vibecoding, 2025).
Neither of those is complaining. Both are describing the same mechanism, and that mechanism is measurable. Four things are happening inside the agent at once, and they compound.
1. Context rot: the window fills up and the model forgets
Every frontier model — Claude, GPT-5, Gemini 2.5 Pro, Opus 4.x — is advertised with a huge context window of 200K or 1M tokens. The window is real. The useful window is much smaller.
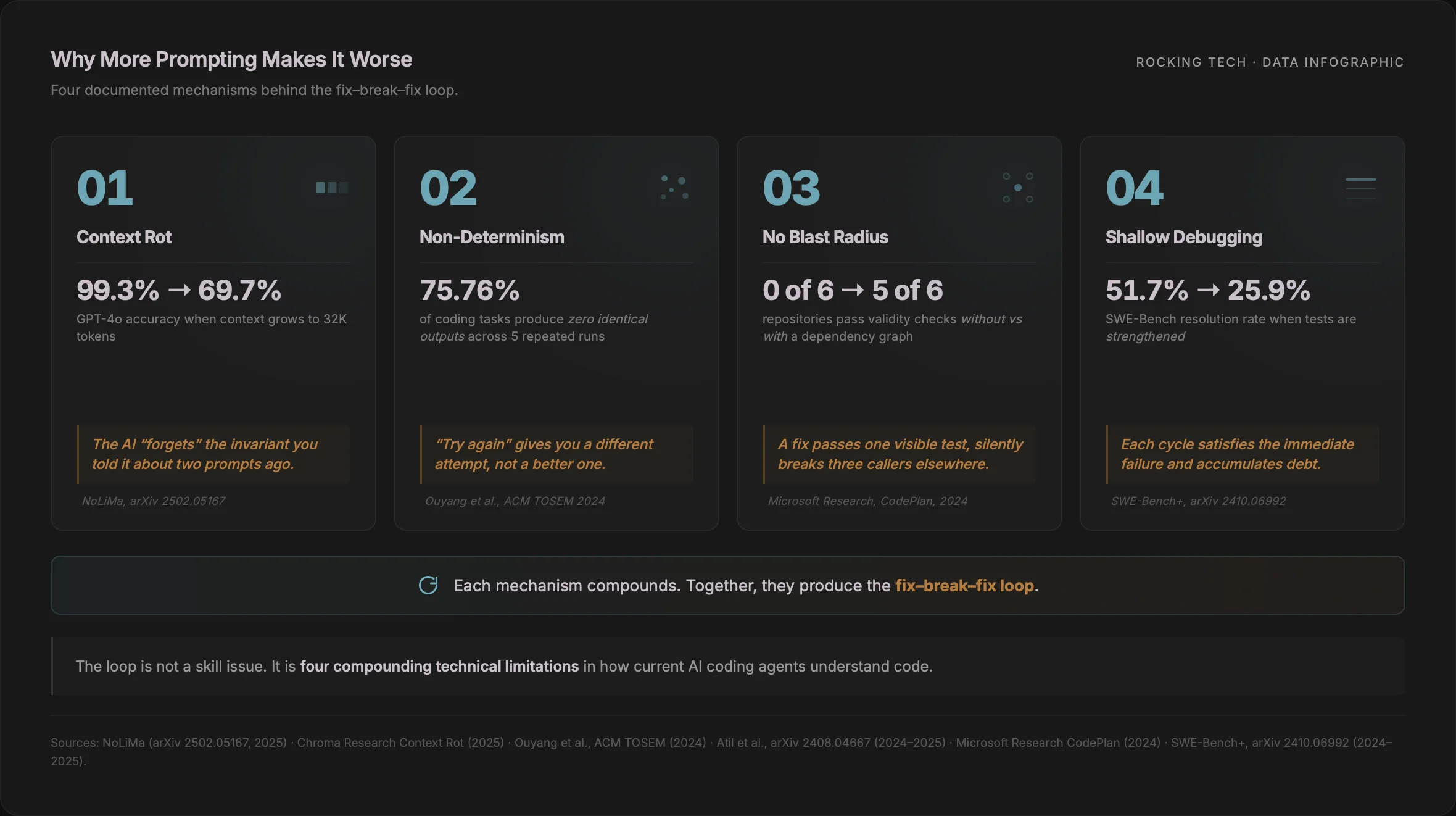
Chroma Research's Context Rot study of 18 frontier models (including GPT-4.1, Claude 4, Gemini 2.5, Qwen3) found that "models do not use their context uniformly; instead, their performance grows increasingly unreliable as input length grows", even on trivial repeat-the-string tasks (Chroma Research, July 2025). The NoLiMa benchmark tested 12 long-context LLMs and found 10 of them dropped below 50% of their short-context baseline at just 32K tokens; GPT-4o fell from a 99.3% baseline to 69.7% at 32K (NoLiMa, arXiv 2502.05167, 2025). Anthropic's own engineering team frames the same phenomenon as an operating constraint: "context must be treated as a finite resource with diminishing marginal returns" (Anthropic Engineering, 2025).
Every time you paste the error log, the previous reply, the file in question, and "also don't break X" back into the chat, you are pushing real signal deeper into a window where the model is demonstrably less able to use it. The fix arrives having forgotten the invariant you told it about two prompts ago — because, functionally, it has.
2. Non-determinism: the same prompt does not return the same code
Founders often assume a regenerated fix is a better version of the same attempt. It is not. It is a different attempt.
An empirical study in ACM Transactions on Software Engineering and Methodology ran ChatGPT through 829 coding problems across three benchmarks, five times each. The proportion of tasks producing zero identical test outputs across the five runs was 75.76% on CodeContests, 51.00% on APPS, and 47.56% on HumanEval — and setting temperature to zero reduced the effect but did not eliminate it (Ouyang, Zhang, Harman & Wang, ACM TOSEM, 2024). A follow-up study of five LLMs across eight tasks measured up to 15% accuracy variance and a best-versus-worst gap of 70% at nominally deterministic settings (Atil et al., arXiv 2408.04667, 2024, revised 2025; published at Eval4NLP 2025). A further paper attributed much of the residual randomness to GPU type, GPU count, and batch size — meaning the infrastructure your request happens to land on changes the code you get back (Yuan et al., arXiv 2506.09501, June 2025; NeurIPS 2025).
When your first fix breaks two other things and you reflexively re-prompt "try again", you are not asking the same question twice. You are rolling a fresh die on different hardware. Each attempt can legitimately produce a different architecture, different variable names, and different side effects.
3. No blast radius: the agent edits without a map
This is the single most important mechanism, and the least understood by non-technical founders. The popular AI coding agents do not build a language-aware, cross-file dependency graph before editing your code. They rely on embedding retrieval plus grep/glob search. Anthropic's own engineering post on context is explicit about the approach: their agent design uses "primitives like glob and grep" to navigate codebases, rather than indexing a syntax tree (Anthropic Engineering, 2025). Translation: the agent searches for text that looks related. It does not traverse a real call graph.
The measurable cost is large. Microsoft Research's CodePlan study ran repository-level coding tasks through GPT-4 with and without an explicit dependency graph. The graph-aware planner passed validity checks on 5 of 6 repositories; the identical LLM without the planning graph passed 0 of 6 (Microsoft Research, CodePlan, 2024).
Without a call graph, the agent cannot see that the authentication helper it is rewriting is invoked by four controllers, two Artisan commands, and a queued job. Its "fix" passes the one test it can see and silently breaks three callers you'll only notice in the next prompt cycle. Every additional prompt widens the blast radius the agent never computed.
4. Shallow debugging: patching the symptom, not the cause
LLM coding agents preferentially address the most recently-quoted error line rather than the upstream cause. The SWE-Bench+ audit manually reviewed 251 successful GPT-4 patches and found that 31.08% passed only because of weak test cases — "plausible patches" that were semantically wrong (Aleithan et al., SWE-Bench+, arXiv 2410.06992, 2024). The same work strengthened the test suites and re-ran the leading coding agents: the average resolution rate on SWE-Bench Verified fell from 51.7% to 25.9% once tests could no longer be satisfied by plausible but wrong patches (Aleithan et al., SWE-Bench+, 2024).
The more specifically you paste the error text, the more literally the agent locks onto that line — often wrapping a try/except around it, or special-casing the offending input. That passes the next run, then breaks something one level up the call stack. Because the "plausible patch" passes the test visible to both you and the agent, each prompt cycle satisfies the immediate failure while quietly accumulating debt. That is exactly the fix-break-fix signature.
Put the four together and you have a system that forgets your constraints as the conversation grows, hands you a non-deterministically different attempt each time, edits without knowing what depends on what, and optimises for the visible error rather than the real one. The loop is the emergent behaviour.
What the loop costs while it's happening
The loop has a price, and the price is metered. Tool pricing across the major platforms has shifted through 2025–26 in ways that make regression cycles disproportionately expensive.
Lovable's Pro plan allocates 100 credits on $25 per month. Its "Try to fix" button is officially free, but every Agent-mode prompt that follows is not (Lovable documentation, 2025). One published review logged the exact dynamic: "Lovable attempts a fix, introduces a new bug, attempts to fix that, creates another issue. I watched it burn 12 credits in one loop before I intervened manually. For reference: my Pro plan's 100 monthly credits lasted exactly 14 days at my usage rate" (ohaiknow review, 2026).
Cursor restructured its $20 Pro plan on 16 June 2025, moving from "500 fast responses plus unlimited slower responses" to a $20 API-priced usage budget per month, with overages requiring manual top-ups. The backlash was severe enough that Anysphere CEO Michael Truell issued a public apology on 4 July 2025: "We recognize that we didn't handle this pricing rollout well and we're sorry. Our communication was not clear enough and came as a surprise to many of you" (Truell, Cursor blog, 4 July 2025).
Replit Agent 3, launched 10 September 2025, produced the sharpest spike. Within days, The Register was reporting users going from $100–250 per month to over $1,000 in a single week, quoting one user directly: "editing pre-existing apps seems to cost most overall — I spent $1k this week alone" (The Register, 18 September 2025). Replit's checkpoints bill regardless of outcome, spending caps are not configured by default, and usage-based charges are non-refundable within the 30-day evaluation window (The Register, September 2025).
The pattern across the tools is identical. Regression loops are among the most expensive failure modes because each iteration carries full generation cost and produces a non-deterministic attempt that may require another. The tools that advertise "try to fix — free" tend to move the cost to the next message. The ones that don't just bill you twice.
A separate article in this cluster covers the broader rescue economics when the tool-level spend spills into freelancer and agency fees; this piece stays focused on what's happening inside the code.
What the moment actually sounds like
What makes the loop particularly corrosive is how it presents emotionally. The research describes context rot and non-determinism as statistical properties. Founders experience them as betrayal. A handful of specific moments recur across reviews, forums, and Reddit threads from late 2025 and early 2026.
There is the moment of realisation. A three-month Cursor review on r/CursorAI captured the productivity-negative version: "Without CursorAI: a MVP-project takes 1 week. With CursorAI: the same project still takes 7 days — plus another 3 weeks to clean up the mess it introduced" (r/CursorAI, April 2025). The realisation is never that the AI is stupid. It's that persistence has stopped paying.
There is the confidently-wrong fix. One published Lovable review described the loop almost as a numbered protocol: "1. You ask lovable to fix the Problem. 2. Lovable will tell you that the issue is now fixed. 3. You realize, its not. 4. start at 1" (Fact Checker review of Lovable, 2026). The AI's confidence is the reason the loop continues. If it said "I'm not sure", the founder would stop.
There is the disappearing feature. A Cursor user wrote on the official forum: "Cursor has started editing the wrong files, breaking parts of my codebase unintentionally. On a few occasions, it has even deleted files entirely" (Cursor forum, 2025). These are not rare incidents. They are the logical consequence of blast-radius blindness.
And there is the decision to hire a human. A post in r/VibeCodeDevs captured the exact language founders use at the inflection point: "I've actually already built a 70%-there prototype using Lovable, though it took me around 5 hours and was a somewhat frustrating experience. I also have no coding background… I'd love to hire someone to build it for me, but places like Upwork hardly have anyone using AI tools. It's hard to pay a traditional dev agency for 2 weeks of dev work knowing that I already made a version with most of the features in a few hours with no experience" (r/VibeCodeDevs, May 2025).
Note the particular shape of that frustration. It is not a rejection of vibe-coding. It is a recognition that the 70-to-100% gap needs a different skill.
The common thread is worth marking. Founders don't describe the tools as stupid or broken. They describe themselves as stuck, as uncertain whether progress is being made, as unsure what changed. That's the rational response to a system that is non-deterministically rewriting their code without a dependency graph while losing track of constraints — but experienced from the outside, it feels like a personal failing. It isn't.
What actually works: the architectural intervention
The loop cannot be prompted out of. You cannot context-engineer your way past context rot, and you cannot instruct an agent to build a dependency graph it doesn't maintain. Escaping the loop requires treating the vibe-coded codebase as what it actually is — an untrusted, undocumented legacy application that happens to be a week old — and applying the same diagnostic tools an engineer uses on any inherited codebase.
Three things need to happen, in order.
Static analysis with real thresholds. The single most useful tool for most vibe-coded repos is jscpd — the copy-paste detector — because the dominant defect in AI-generated code is duplication. A GitClear analysis of 211 million lines of code authored between 2020 and 2024 found that copy-pasted code rose from 8.3% to 12.3% of all changes, duplication blocks increased roughly eightfold, and the share of refactored ("moved") lines fell from 24.1% in 2020 to 9.5% in 2024 (GitClear, AI Copilot Code Quality, 2025). For Laravel back-ends, PHPStan with the Larastan extension catches AI-invented Eloquent methods the human reader doesn't notice; Psalm's taint analysis catches unsanitised input flowing to SQL and shell sinks, which AI-generated controllers miss routinely. SonarQube's published AI Code Assurance guidance recommends tightening the default quality gates specifically for AI-generated code (Sonar, 2025).
A dependency-graph pass the agent was never able to do. For a React or TypeScript vibe-coded app, madge --circular src/main.ts and madge --orphans immediately surface the circular imports and dead files agent edits leave behind. For a Laravel back-end, php artisan route:list separates routes that actually serve traffic from the duplicate CRUD scaffolding AI agents create (/users/list and /users/index, pointed at the same controller, happens more often than is comfortable). What this gives you is the call graph the agent never had, which in turn tells you which files are genuinely load-bearing and which are decoration. The mechanics are covered in more depth in our Laravel inheritance audit guide.
Patch-versus-rewrite, decided on evidence. Two recently-published engineer teardowns show what this looks like in practice. Eric J. Ma's "Undoing AI vibe-coded slop with AI" (29 March 2026) documents the refactor of canvas-chat, a project he had built with heavy AI assistance. His own framing: "a functional, but tangled, 8,500-line app.js monolith" that he then wrangled "into a clean, modular plugin system" (Ma, 2026). His conclusion is diagnostic: "The AI could add features, fix bugs, and split files when prompted. But it couldn't see the latent architecture — the system that would make the whole thing maintainable" (Ma, 2026). The mechanism he describes is the same one in the literature above — the AI executes architecture, it does not design it.
A separate review of six unrelated vibe-coded codebases found near-identical patterns: four of the six had authorisation gaps where API routes authenticated users but did not authorise them against specific resources; five of the six had the same generic try/catch block swallowing every async failure — the exact pattern catch (error) { console.error(error); return { error: "Something went wrong" } }, repeated in nearly every async function (JSGuruJobs, I Reviewed 6 Vibe Coded Codebases, dev.to, 12 February 2026). (We covered the security side of this pattern separately.)
What both teardowns make clear is that the intervention is not "fix the bugs". It is imposing the architecture the AI could not see — typically by extracting pure functions, isolating feature modules behind explicit interfaces, and introducing an end-to-end test suite first so the subsequent refactor (even an AI-assisted one) cannot silently regress. Martin Fowler's Strangler Fig pattern, originally from 2004, applies almost without modification: front the vibe-coded monolith with a thin facade, route one endpoint at a time through a properly-architected replacement, and retire the original incrementally (Fowler, 2004). The pattern works because it replaces non-deterministic edits-in-place with deterministic route-level migrations that can be verified.
The rewrite-versus-patch test, honestly
The hardest conversation with a founder in the loop is not technical. It is whether to keep patching at all.
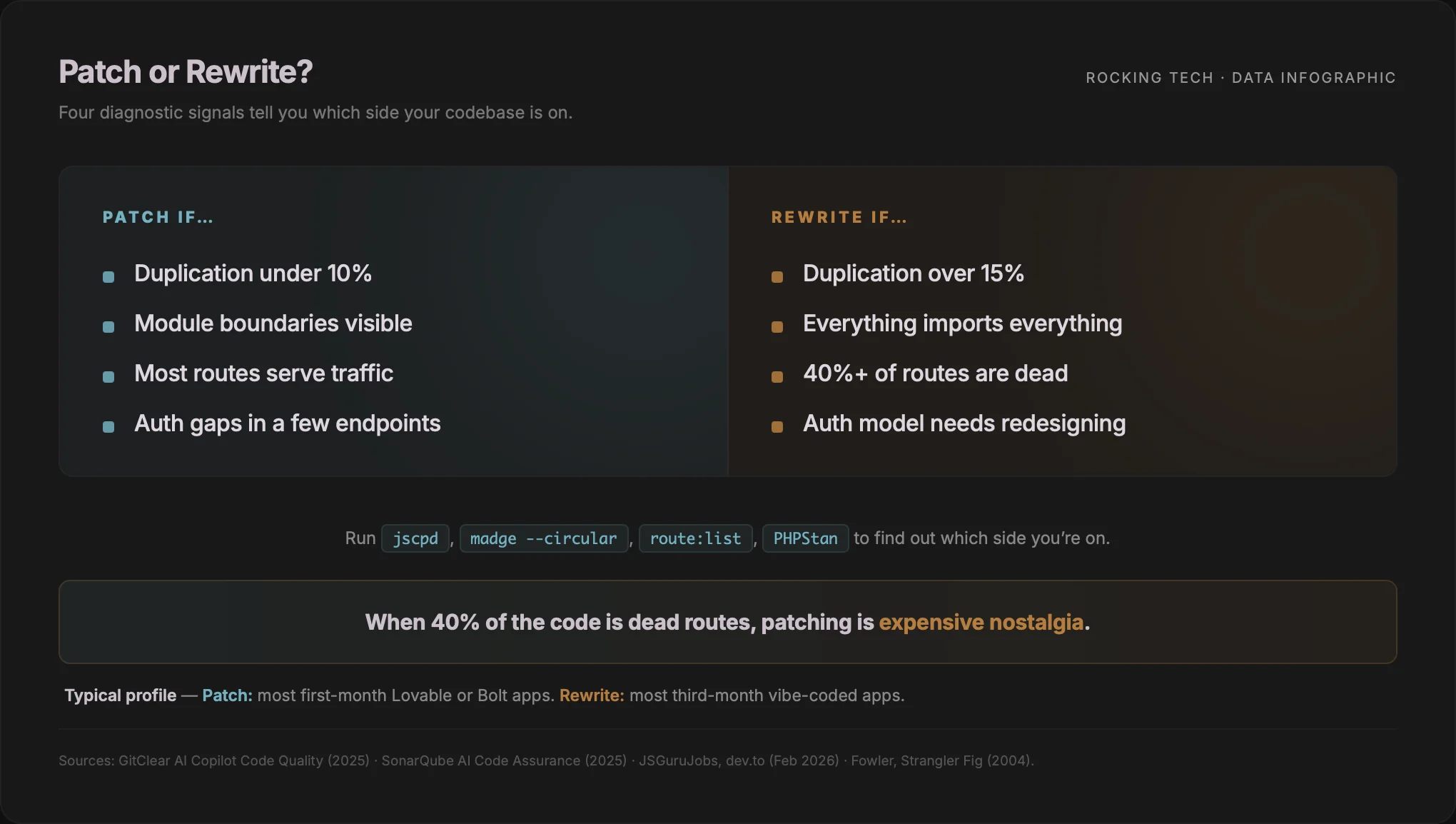
The evidence-based answer comes from the diagnostics above, not intuition. A patch is defensible when duplication is low and localised, there is a coherent module boundary still visible in the code, the authorisation gaps are contained to a small set of endpoints, and the test suite can be backfilled around the existing shape. That profile fits most first-month Lovable and Bolt apps, and a disciplined refactor usually lands in 1–3 weeks.
A rewrite is cheaper when duplication is pervasive, the call graph shows no coherent module boundaries, there is no test suite to anchor a refactor, and the authorisation model needs redesigning rather than patching. That profile fits most third-month vibe-coded apps — and specifically, most apps where the founder has been in the loop long enough to get here.
The signal to look for is not how broken the app feels. It is how much of the code the diagnostics say is load-bearing versus decorative. When Madge and route:list tell you 40% of the code is unreachable, patching it is expensive nostalgia.
How we approach this
There are a small number of UK agencies now positioned specifically for vibe-coded app rescue. Most are less than a year old, pricing ranges from the low hundreds of pounds for a quick code-repo look to four-figure fixed retainers, and almost none have published case studies yet. That's the market. Here is how we run it.
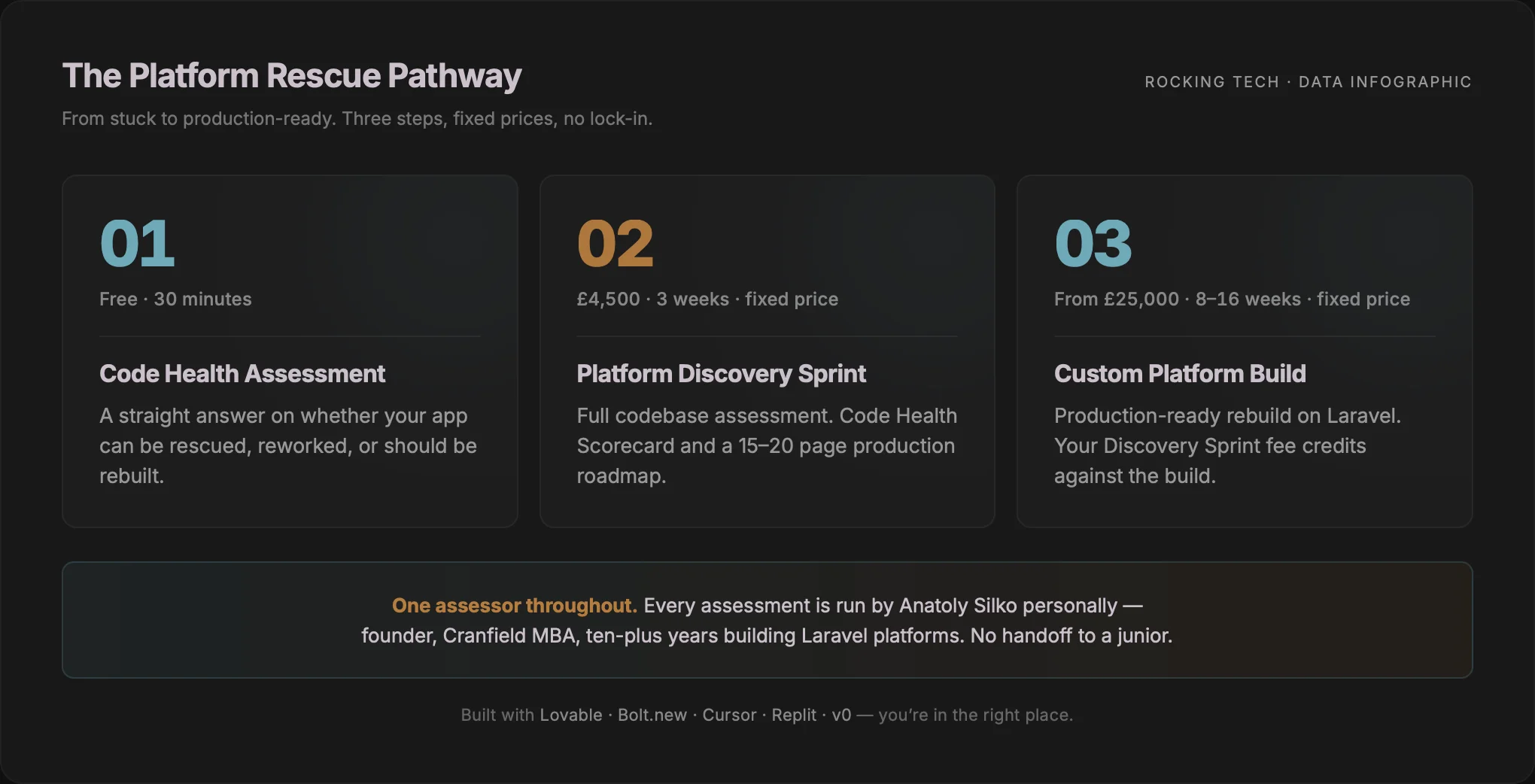
A Platform Rescue engagement at Rocking Tech begins with a free 30-minute Code Health Assessment. The purpose of that call is to determine whether your app can be rescued, needs rework, or should be rebuilt — and to be honest if the answer is none of the three. If off-the-shelf software would serve you better than a bespoke platform, we will tell you that on the call.
If the right next step is a full diagnosis, the Platform Discovery Sprint is a fixed-price £4,500, three-week engagement that produces a Code Health Scorecard and a 15–20 page production roadmap. The Sprint runs the diagnostics described above — static analysis on duplication, cognitive complexity and test coverage; dependency-graph analysis; and route-level traffic verification — and returns a scorecard that grades each finding with a fix, refactor, or rebuild recommendation. You end the Sprint knowing exactly what's salvageable, what it costs to stabilise, and whether rebuilding is the cheaper option.
If a rebuild is the right call, the Sprint feeds directly into a Custom Platform Build, fixed-price from £25,000, 8–16 weeks, on Laravel. The £4,500 Discovery Sprint fee is credited in full against the build. Existing React or Supabase front-ends are preserved where the front-end is solid — we rebuild the backend on Laravel and reconnect via Inertia.js rather than force a full-stack rewrite you didn't need.
I run every Platform Rescue assessment personally. You are not handed off to a junior developer who has not seen a vibe-coded codebase before. Ten-plus years building and rebuilding Laravel platforms, and an MBA from Cranfield, gives me a particular angle on this work: the technical diagnosis is rigorous, but the framing is always a business decision — what is the fastest path to a production-ready platform you can ship with, and what does that cost.
What to do this week
If you are currently 20 prompts deep into a fix-break-fix cycle, the single most valuable hour you can spend is not another prompt. It is running three diagnostics against your repo — jscpd for duplication percentage, madge --circular for cyclic and dead-file imports, and your framework's equivalent of php artisan route:list — and writing down the three numbers they produce.
Those three numbers will tell you more about whether you are one prompt or one rewrite away from a working app than another £200 of credits will.
The loop is not a prompting problem. It is a diagnostic problem being managed with a prompting tool. Once you have the diagnosis, the intervention — patch, refactor, or Strangler Fig rewrite — is a decision you can make with numbers instead of frustration.
More prompting makes AI code regression loops worse because four compounding mechanisms — context rot, non-determinism, absent dependency graphs, and symptom-patching bias — each make every additional prompt more likely to break something working rather than less. The literature now measures all four. The cost is in credits for as long as you stay in the loop, and in unshipped weeks for as long as you stay in denial about the loop.
The exit is architectural. Diagnose with static analysis and dependency tools first. Decide patch-versus-rewrite on evidence. Then intervene with the discipline the AI was never going to supply itself.
Vibe coding built the app. It cannot, on current evidence, finish it — not because it's stupid, but because it's blind to exactly the thing that now matters most: the shape of what you already have.
Stuck in the fix-break-fix loop?
Starts with a free assessment call · Discovery Sprint £4,500 · Full rebuilds from £25,000
Prefer email? hello@rockingtech.co.uk