What It Actually Costs to Fix a Vibe-Coded MVP

The question arrives in roughly the same language regardless of which tool built the app. On Indie Hackers, a founder described giving up on Lovable after twenty attempts: "I don't have a lot of money — if any budgeted to do this — as I thought I could get it done in Lovable" (Indie Hackers, September 2025). On the Cursor Community Forum, another lost days backtracking after the AI "scraps my entire design, layout, functionality, import calls, dependencies, etc… EVERYTHING" (Cursor Forum, February 2025). On the Lovable Feedback Portal, the complaint is almost identical: "when you try to tell Lovable to fix the thing it broke to be exactly the same as it was already done before — it is never able to do it. It starts running around in circles, hallucinating."
The pattern is consistent enough to have its own vocabulary now. The frustration cycle — fix one thing, break ten others, burn credits, get nowhere — is not a skill issue. It is a documented, measurable limitation of how these tools work.
This article explains what professional rescue actually involves, why the cost varies so widely, and how the answer changes depending on what the code assessment reveals. No exact prices — they depend entirely on your specific codebase. But by the end, you will understand the three tiers of intervention, what determines which tier your app falls into, and why "how much" is the wrong first question.
The reason nobody can give you a number over email
A greenfield build starts from a known state: nothing. A rescue starts from an unknown state: something, built by a tool that made thousands of undocumented decisions without understanding your business. The scope of a rescue is whatever the assessment reveals, and it varies wildly between codebases that look superficially similar.
The McKinsey/Oxford BT Centre study of 5,400 IT projects found that large projects average 45% over budget and deliver 56% less value than predicted (McKinsey, 2012). That is for projects with professional scoping. A rescue engagement against an undocumented, AI-generated codebase has materially more scope uncertainty than a greenfield build — and subsequent research confirmed that IT project overruns follow a power-law distribution, meaning tail risk on scope-uncertain work is not just higher than average, it is higher than naive estimation suggests (Flyvbjerg & Budzier, 2022).
The practical consequence: any agency quoting you a fixed rebuild price based on a 30-minute call is either padding the quote by 50–100% to cover their risk, or planning to hit you with change orders once the real scope emerges. Neither outcome serves you.
This is why the rescue market in the UK overwhelmingly operates on one of two models: time-and-materials with a discovery phase first, or a fixed-fee assessment that produces a scoped quote for the work that follows. The assessment is the quote — everything before it is a guess.
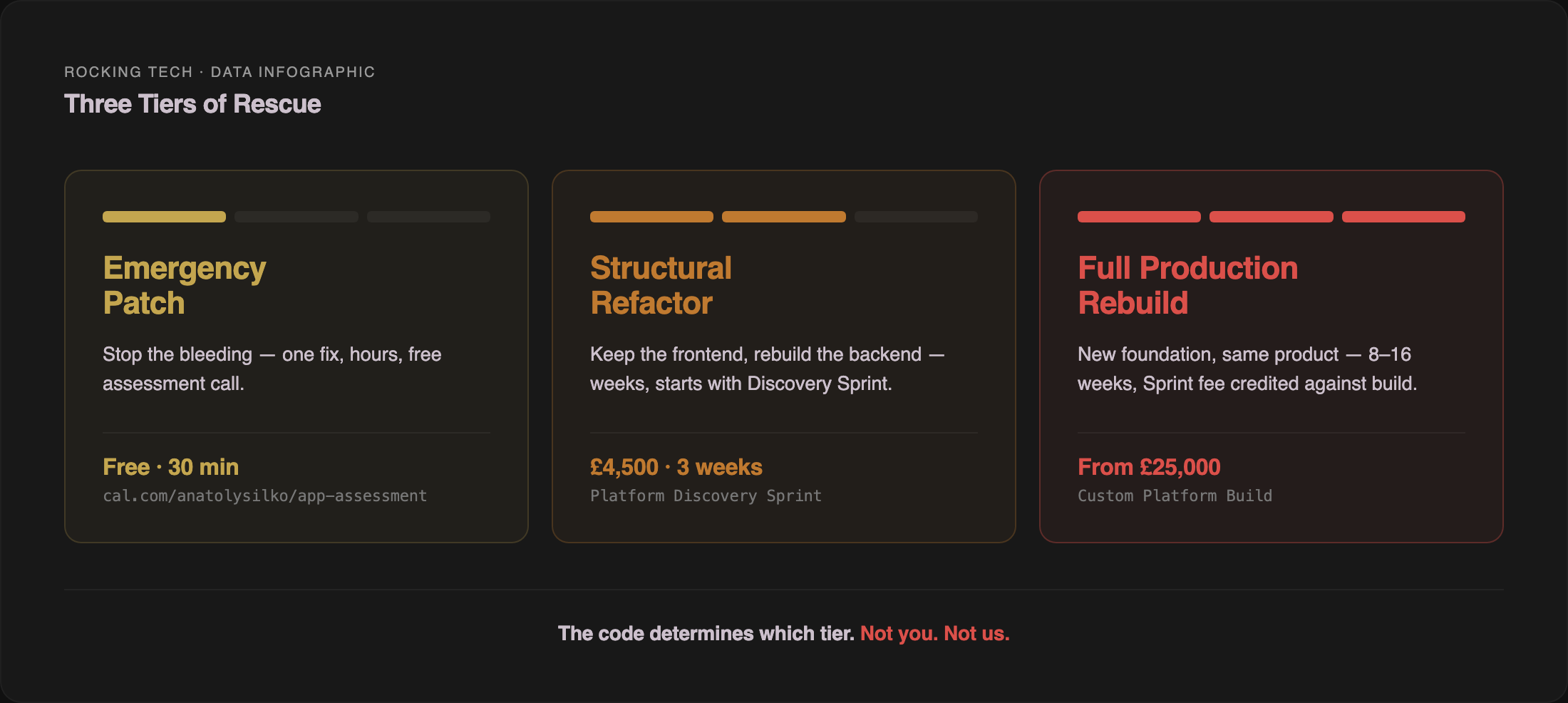
Three tiers of intervention
Every rescue engagement we have assessed falls into one of three categories. The categories are not a menu you choose from — they are a diagnosis the codebase determines.
Tier 1: Emergency patch
What it is. A targeted fix for a specific, urgent problem — the site is down, payments are failing, a security vulnerability has been discovered, or the app crashes after login. The goal is not to make the codebase healthy. It is to stop the bleeding.
What it typically involves. Identifying the specific failure, applying a fix, and verifying it works. Hours of work, not days. The fix is often temporary — it stabilises the immediate problem without addressing the underlying architecture that caused it.
When it applies. When you have real users or revenue at risk and something has broken in production. The DSIT Cyber Security Breaches Survey 2025 found the average cost of the most disruptive breach at £3,550 for businesses when excluding zero-cost incidents (Ipsos, 2025). A separate survey of 504 UK business leaders found UK businesses lost £3.7 billion to internet failures in 2023, with 15% of businesses losing money the moment connectivity fails (Beaming/Censuswide, 2024). The cost of the emergency is real. The cost of leaving it unfixed is higher.
What it does not do. An emergency patch does not make your app production-ready. It does not fix the security failures that appear in virtually every AI-generated codebase. It does not address the structural issues that will cause the next emergency. Think of it as a tourniquet, not surgery.
UK market context. Emergency developer rates in the UK range from £250 for a fixed-price urgent fix to £75–£200 per hour at agency rates, depending on urgency, out-of-hours requirements, and complexity (Osdire, Patternica, Red Eagle Tech, 2026). Most UK agencies do not publish emergency pricing because scope cannot be determined before triage.
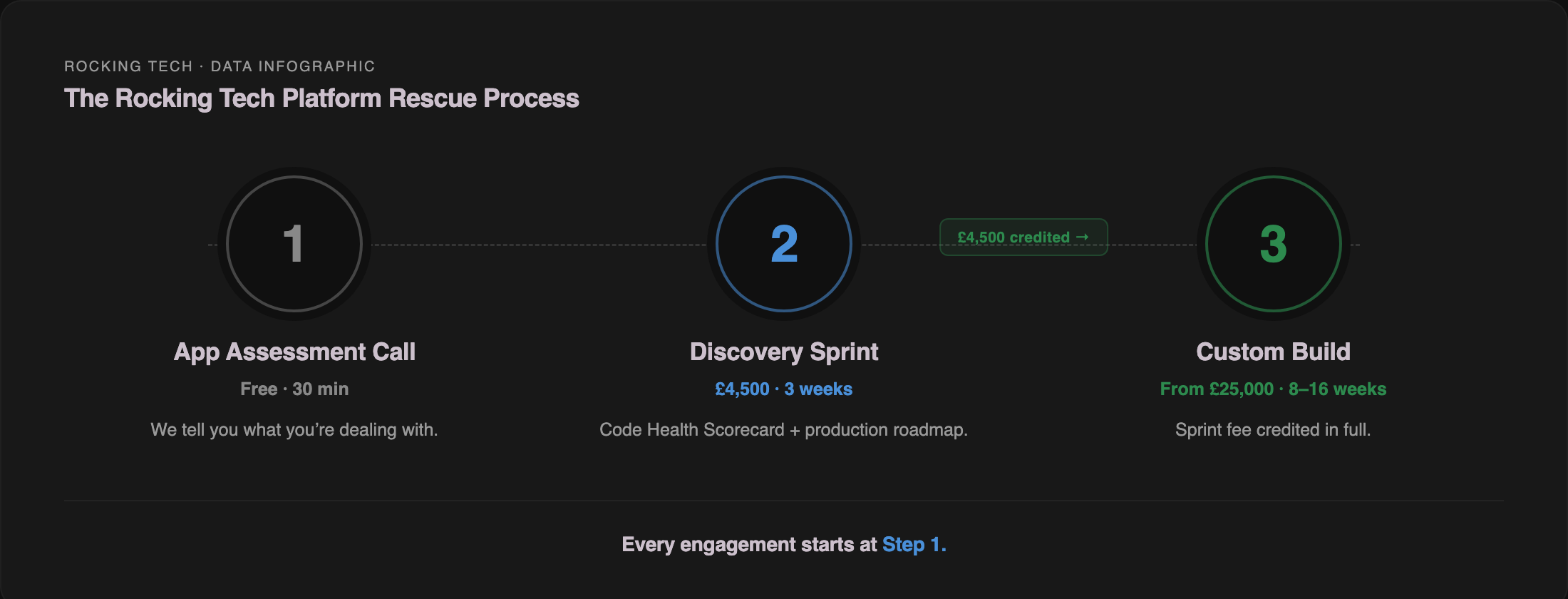
How we handle it. Our free App Assessment Call — 30 minutes, no charge, no commitment — is the triage step. If the problem is genuinely a quick fix, we will sometimes point you in the right direction on the call at no cost. If the emergency reveals deeper structural issues (and it usually does), we recommend the Discovery Sprint rather than an open-ended hourly engagement that risks running up a bill without solving the root cause.
Tier 2: Structural refactor
What it is. Keeping the parts of your app that work — typically the frontend, the UI components, the Tailwind styling, the validated user flows — and rebuilding the parts that do not: the backend architecture, authentication, database design, security layer, and error handling.
What it typically involves. A proper assessment of the codebase, followed by weeks of targeted engineering work. The frontend your users already know stays intact. The backend gets rebuilt on a production framework with proper error handling, security, and test coverage. This is the tier where most vibe-coded apps land — the three architectural failures are almost always in the backend, not the frontend.
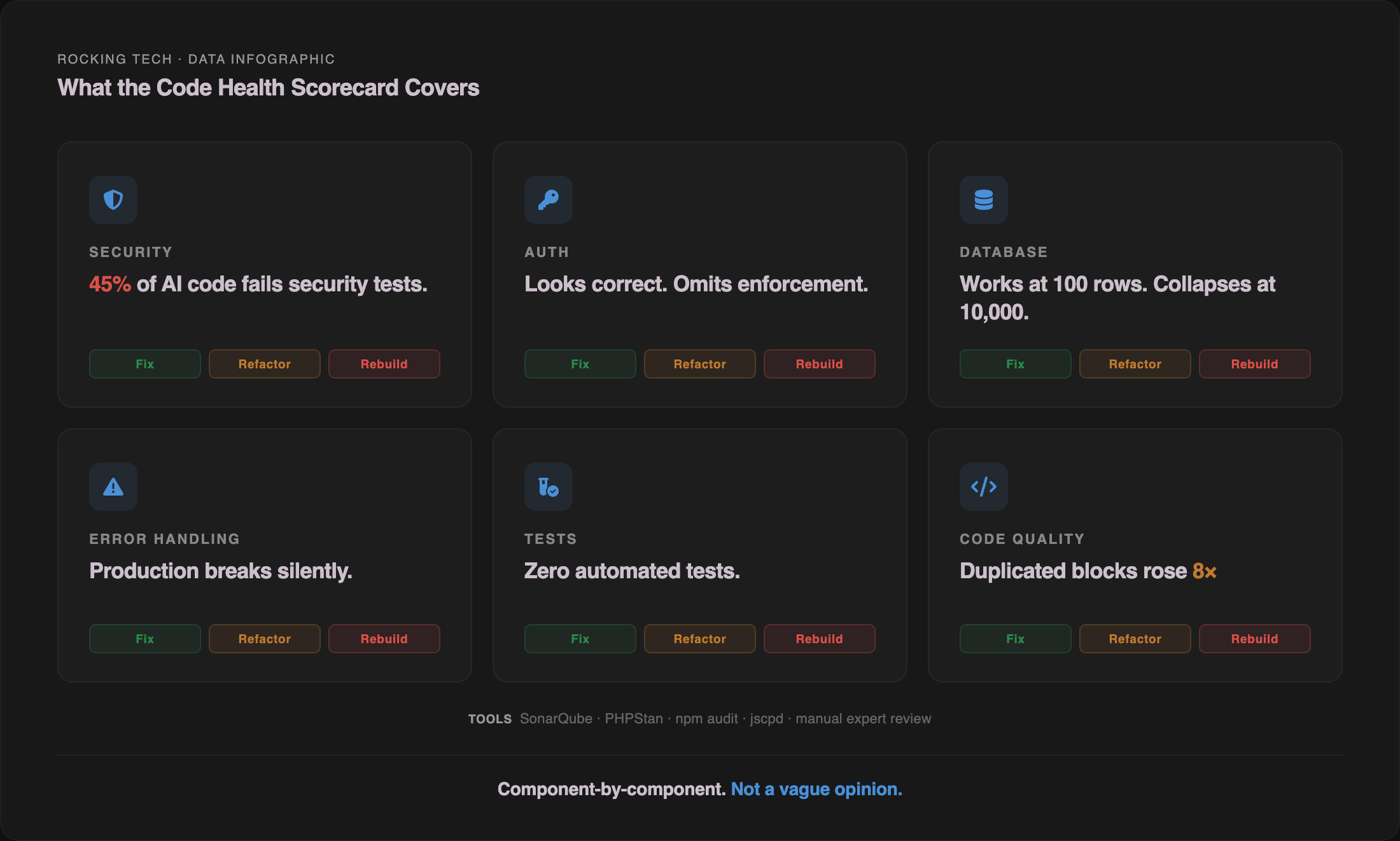
When it applies. When the app has genuine value — validated users, revenue, a proven concept — but the technical foundation cannot support production traffic, multiple users, or regulatory requirements. The Veracode 2025 GenAI Code Security Report tested 150+ LLMs across 80 coding tasks and found 45% of AI-generated samples failed security tests (Veracode, 2025). The CodeRabbit analysis of 470 real-world GitHub pull requests found AI-co-authored code averaged 1.7× more issues per PR than human-written code, with security vulnerabilities 1.5–2.7× higher (CodeRabbit, 2025). If your app was built with AI tools and has not had a professional security review, the statistical bet is that it has problems in this category.
What gets preserved versus rebuilt. Practitioner consensus across the agencies I have reviewed (and from our own assessments) points to a consistent layered pattern: frontend components, Tailwind classes, and shadcn/ui primitives are largely preservable — they are already production-grade libraries. Design assets and brand are fully preserved. Routing logic converts mechanically. The database schema typically needs normalisation, proper indexes, soft deletes, and RLS policies. Business logic is often partially rewritten. Authentication and billing layers are almost always rebuilt from scratch.
UK market context. Refactor engagements in the UK typically start at £5,000 for light stabilisation work and run to £15,000–£40,000 for a substantive backend rebuild, based on UK senior developer day rates of £450–£650 and project durations of two to eight weeks (IT Jobs Watch, Patternica, 2026). The range is wide because the scope depends entirely on what the assessment reveals.
How we handle it. A refactor engagement always starts with the Platform Discovery Sprint — £4,500, three weeks, fixed fee. The Sprint produces a Code Health Scorecard: automated scanning with SonarQube, PHPStan, and npm audit, plus expert manual review, producing a severity-prioritised list of issues with a fix, refactor, or rebuild recommendation per component. You end the Sprint with a written 15–20 page report, an architecture diagram, a phased roadmap with budget ranges per phase, and a clear answer on what is salvageable and what is not. I run every assessment personally — you are not handed off to a junior who has not seen a vibe-coded codebase before.
If the refactor leads to a Custom Platform Build, the £4,500 Discovery Sprint fee is credited in full against the build cost.
Tier 3: Full production rebuild
What it is. Starting the technical implementation from scratch, using your existing app as a living requirements document. The original prototype is not thrown away — it is treated as the most expensive, most detailed specification you could have written. Every screen, every user flow, every edge case your beta testers discovered is preserved as knowledge. What gets replaced is the code underneath.
When it applies. When the assessment reveals that the codebase is so entangled that fixing individual components would take longer than rebuilding — typically when technical debt exceeds 70–80% of the codebase, when there is no coherent module boundary visible, when the authorisation model needs redesigning rather than patching, or when the test suite is nonexistent and cannot be backfilled around the existing shape.
The "70% problem." Addy Osmani, Head of Chrome Developer Experience at Google, coined the phrase in December 2024: "AI can rapidly produce maybe 70% of the code… the obvious patterns. But the remaining 30% — edge cases, debugging, integration with production systems, security — can be just as time consuming as it ever was" (Osmani, 2024). One practitioner documented a Lovable SaaS prototype built in three hours that then required four days of engineering work to deploy to Railway — hardcoded environment variables, SQLite-to-PostgreSQL syntax breakage, Stripe webhook signature failures, OAuth redirect failures, N+1 queries, and five-to-ten-second page loads (Blending Bits, 2025). The last 30% is not 30% of the effort. It is where the effort concentrates.
The rewrite trap — and how to avoid it. Joel Spolsky's "Things You Should Never Do, Part I" (2000) — the canonical argument against full rewrites — is still being validated by current practitioners. The risk is real: rewrite projects often take 2–2.5× the initial estimate once catch-up costs, undiscovered scope, and adoption enhancements are factored in. Martin Fowler's Strangler Fig pattern, updated in August 2024, is the alternative: replace legacy components incrementally while the application keeps running, rather than betting the business on a multi-month parallel rebuild. The pattern works because it replaces non-deterministic edits-in-place with deterministic route-level migrations that can be verified one at a time. We covered the Strangler Fig approach in detail in our rescue costs article.
UK market context. Full MVP rebuilds in the UK range from £12,500 for a two-week sprint on a simple app to £60,000–£150,000+ for complex multi-tenant SaaS with payment processing, role-based access, and third-party integrations (Clutch, Fourmeta, Sigli, 2025–2026). The range is enormous because the scope is enormous.
How we handle it. A rebuild at Rocking Tech is a Custom Platform Build — fixed pricing, 8–16 weeks, built on Laravel with Vue.js. The Discovery Sprint always comes first. Anyone quoting you a rebuild timeline without assessing the codebase is guessing — that is not how we work, and it is not how the good agencies in this market work either. If the honest answer from the Sprint is "use off-the-shelf software," we say that. If the answer is "your frontend is solid and the problems are backend-only," we rebuild the backend on Laravel while preserving your React frontend via Inertia.js. The Discovery Sprint determines the answer; the rebuild executes it.
What determines which tier you fall into
You cannot choose your tier the way you choose a menu item. The codebase determines the tier, and the assessment reveals the codebase. But there are signals you can observe yourself before the assessment begins — signals that shift the probability toward one tier or another.
Signals that suggest Tier 1 (emergency patch). A specific, isolatable failure: the site went down after a hosting change, a Stripe webhook stopped firing after a Supabase migration, an SSL certificate expired, a single API endpoint is returning 500 errors. The app was working yesterday. Something specific broke.
Signals that suggest Tier 2 (structural refactor). The app works for you but breaks for other users. Authentication fails with concurrent sessions. Database queries slow to a crawl beyond a few hundred records. Payments succeed in test mode but fail in production. You have been in the fix-one-thing-break-ten-others loop for weeks. You can demonstrate the app to investors but you cannot invite 50 beta testers without it falling over.
Signals that suggest Tier 3 (full rebuild). The codebase is so tangled that no developer — human or AI — can confidently change one file without breaking three others. There is no test coverage and no way to add it without restructuring. The database schema does not match the actual data model of your business. Authentication was bolted on as an afterthought and cannot be extended to support roles, teams, or permissions. Multiple developers have looked at the code and each said some version of "I'd need to start again." The METR randomised controlled trial found that experienced developers using AI tools were actually 19% slower than working without them on their own mature repositories — though a follow-up with returning participants showed improvement once tool familiarity increased (METR, 2025). Once a codebase has passed the complexity threshold, AI tools make it worse, not better. That is the rebuild signal.
No published study quantifies what percentage of vibe-coded apps fall into each tier. The closest empirical slice is the Wiz Research scan of 1,645 Lovable showcase apps, which found that approximately 10% had structural security failings consistent with the "needs rebuild" category (Wiz/CVE-2025-48757, 2025) — though that measures one specific vulnerability class on one platform, not a tier distribution. Practitioner estimates cluster around 10–15% patchable, 50–60% refactorable, 25–35% needing substantial rebuild — but treat those as informed intuition, not data.
Why "how much to fix my app" is the wrong first question
The question founders actually need answered is not "how much" — it is "what am I dealing with." The cost follows from the diagnosis. Asking "how much to fix my app" before anyone has looked at the code is like asking "how much to fix my car" over the phone. The answer depends on whether you need a new tyre or a new engine, and the only way to know is to open the bonnet.
This is the structural reason the UK rescue market operates the way it does. Agencies that quote fixed prices sight-unseen are either overcharging to cover scope risk (reasonable, but expensive for you) or undercharging and planning to make it up in change orders (less reasonable, and more expensive for you in the end). The agencies that get the best outcomes — in this market and in any professional-services market where the scope is discovered, not specified — charge for the assessment separately and let it determine what follows.
The sunk-cost dynamic makes this harder than it should be. Founders who have already spent £500–£2,000 on AI tool subscriptions, weeks of their own time, and possibly thousands more on freelancers who did not deliver are psychologically anchored to the amount they have already invested. Anchoring research — replicated extensively since the original 1974 study, including a 2025 PMC study confirming the effect is stronger when the buyer is less familiar with the item being priced (Tversky & Kahneman, 1974) — means the first number a founder hears becomes the reference point against which all subsequent prices are evaluated. If a Fiverr gig costs £50 and the Discovery Sprint costs £4,500, the Sprint feels 90× more expensive. It is not. The Fiverr gig fixes one symptom. The Sprint diagnoses the disease and tells you what the treatment costs. They are not comparable services, but the anchoring effect makes them feel like they are.
The correct comparison for the Discovery Sprint is not a Fiverr gig. It is the cost of commissioning a build — or continuing to pour money into a broken codebase — without knowing what you are dealing with. One practitioner comparison published in 2026 priced a multi-tenant SaaS rebuild from a Lovable prototype at $30,000–$60,000, versus $15,000–$35,000 for building it correctly from scratch (Chrono Innovation, 2026). The rebuild costs more than doing it right the first time. The Discovery Sprint exists to determine which path you are on before you commit the larger spend.
The regulatory clock is already running
This section is uncomfortable but necessary. If your vibe-coded app collects personal data from UK users — email addresses, names, payment details, usage data — UK GDPR Article 32 requires "appropriate technical and organisational measures" to protect that data. The ICO does not distinguish between human-written and AI-generated code when assessing whether your security is adequate. A vibe-coded MVP with disabled Row Level Security, hardcoded API keys, and no encryption at rest faces exactly the same enforcement standard as a Fortune 500 application.
The enforcement record is specific. Tuckers Solicitors LLP received a £98,000 monetary penalty in March 2022 — the ICO's first ransomware-related fine — for a stack of basic failings: no multi-factor authentication on remote access, a CVSS 9.8 vulnerability left unpatched for five months despite an NCSC alert, personal data stored in plain text, and a failed Cyber Essentials assessment ten months earlier (ICO, 2022). DSG Retail Ltd's £500,000 fine — upheld at the Court of Appeal in February 2026 — confirmed that inadequate patching, missing firewalls, and failure to follow PCI-DSS hardening guidelines constitute Article 32 failures.
No ICO enforcement action has yet been brought specifically against a founder for security failings caused by AI-generated code. That is an explicit finding, not a gap. The regulator targets the underlying technical failings — missing MFA, no encryption, exposed databases, hardcoded credentials — regardless of whether a human or an LLM wrote the code. A vibe-coded MVP would be judged against exactly the same standard as Tuckers Solicitors.
The insurance picture is no clearer. No UK insurer currently publishes a specific exclusion or premium uplift for AI-generated code in SME cyber or professional indemnity products. But the Lloyd's Market Association describes AI as "software, and so for insurers, AI is a subset of cyber risk," and broker commentary from late 2025 describes the market as in a "silent AI" phase — analogous to the "silent cyber" period of 2015–2020, where policies inadvertently covered risks the underwriters had not priced. The practical implication: your cyber insurance may cover a breach caused by AI-generated code, but the underwriter may not have intended it to, and the exclusion language is coming.
The regulatory clock runs regardless of whether you know it is running. The Discovery Sprint's Code Health Scorecard includes security assessment — SonarQube automated scanning plus expert manual review — precisely because this is the category of finding that carries regulatory consequence, not just technical consequence.
What to do this week
If you are reading this article, you are probably in the fix-break-fix loop right now. You have spent money on AI tool credits, possibly on freelancers, and the app is not getting closer to production. The sunk cost feels heavy. The prospect of spending more feels worse.
Three things are worth doing before you spend another pound.
Run the free self-checks. We published a 30-minute security self-check — seven tests you can run yourself with free tools, right now, to see whether your app has the most common security failures. It covers exposed .env files, hardcoded secrets in frontend code, missing security headers, Supabase RLS configuration, SSL certificates, debug mode in production, and what Google has indexed. If any of those checks come back positive, you have your answer on urgency.
Stop prompting the AI to fix structural problems. The four mechanisms behind the fix-break-fix loop — context rot, non-determinism, absent dependency graphs, and symptom-patching bias — mean that each additional prompt is more likely to break something working, not less. The exit from the loop is architectural, not another prompt. Every credit you burn past this point is money spent making the codebase harder to rescue.
Book the free assessment call. The App Assessment Call is 30 minutes, free, no commitment. I assess whether your app can be rescued, needs rework, or should be rebuilt. If the problem is a quick fix, I will sometimes point you in the right direction on the call at no cost. If it needs a deeper look, the Platform Discovery Sprint — £4,500, three weeks, Code Health Scorecard, 15–20 page report, architecture diagram, phased roadmap — is the assessment that produces a real answer. If the honest answer is "use off-the-shelf software," I will tell you that too.
The Sprint fee is credited in full against any subsequent Custom Platform Build. If you take the deliverable elsewhere — which you are welcome to do — it stands as a complete, portable document.
The question is not "how much to fix my app." The question is "what am I dealing with." The assessment answers that. Everything else follows from the answer.
Stuck in the fix-break-fix loop?
Starts with a free assessment call · Discovery Sprint £4,500 · Full rebuilds from £25,000
Prefer email? hello@rockingtech.co.uk